PG 343: WebBots - Intelligente Internet Softbots
| PG-Zeitraum: |
|
Sommersemester 1999 und Wintersemester 1999/2000 |
| PG-Umfang: |
|
jeweils 8 SWS |
PG-Veranstalter
PG-Aufgabe
Elektronische Medien und speziell das World Wide Web (WWW) gewinnen an immer
stärkerer Bedeutung sowohl für gewerbliche Anwendungen als auch für
unser tägliches Leben. Mit dem neuen Angebot von Informationen geht aber auch
eine steigende Überlastung einher. Nur wenige der angebotenen Informationen
sind für uns interessant und diese gehen vielfach in der Informationsflut
unter. Deshalb brauchen wir Software-Tools, die uns beim Herausfiltern von
für uns relevanten Informationen unterstützen.
Das Information Retrieval stellt hierzu viele Basistechniken zur Verfügung.
Ein Großteil der Informationen auf dem WWW sind als Textdokumente gespeichert.
Mit Methoden des Text Retrievals kann in Suchmaschinen wie
Lycos,
Altavista oder
Excite
in Dokumenten nach Schlüsselwörtern gesucht werden. Obwohl mit diesen
Suchmaschinen bereits einige Erfolge bei der Informationssuche erzielt werden
können, haben sie einige grundlegende Probleme.
- Kein WWW-Katalog ist vollständig:
Durch die hohe Dynamik des WWW kommen ständig neue Dokumente und
Informationsquellen hinzu, während alte wegfallen.
- Es wird nur nach Stichwörtern gesucht, nicht nach Inhalten:
Eine Suchmaschine unterscheidet nicht nach dem Typ der Seite (z. B. Personal
Home Page oder veraltete Seite über eine Konferenz von vor 3 Jahren),
auf der die Schlüsselwörter vorkommen.
Heutzutage werden diese Probleme meist noch manuell behandelt. Angenommen wir suchen
die Personal Home Page einer Person. Zuerst probiert man mehrere Suchmaschinen durch,
bis man den Namen der Person findet. Dann geht man manuell die Liste der Treffer
durch, bis man endlich eine vielversprechende Seite findet. Oftmals ist diese Seite
dann noch nicht die Personal Home Page. Aber vielleicht ist es eine Seite über
ein Projekt, an welchem die Person arbeitet. Von dort gelangen wir dann endlich
über einen Hyperlink zur gewünschten Home Page.
Wenn es mit der Suche nicht so reibungslos klappt, werden wir vielleicht noch andere
Strategien anwenden. Zum Beispiel können wir mit einem der
EMail-Adreßbücher die EMail-Adresse der Persom herausfinden. An der
EMail-Adresse können wir dann den Arbeitgeber bzw. Internet-Provider der Person
ablesen, was uns dann wahrscheinlich zu ihrer Home Page führt. Unzählige
andere Strategien, welche die vielen auf dem WWW verfügbaren Informationsdienste
benutzen, sind ebenfalls denkbar.
In der hier vorgestellten PG soll diese Art von Informationssuche automatisiert
werden. Hierbei soll ein agentenbasierter Ansatz mittels Softbots verwirklicht
werden.
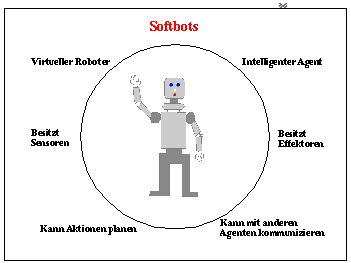
Jeder Softbot ist ein Experte für bestimmte Informationsobjekte, nach denen er auf
Befehl des Benutzers sucht. Dabei sollen Softbots komplexe Strategien anwenden
können, wie sie sonst auch von einem Menschen benutzt würden.
Mögliche Informationsobjekte sind z. B.
- Personal Home Pages
- Projekte
- Institutionen
- Produkte
- Nachrichten
- Publikationen
Agenten können sich auch gegenseitig benutzen. Um z. B. eine Publikation zu finden,
kann man zuerst die Personal Home Page des Authors finden lassen. Mit Methoden der
Textklassifikation erkennt ein Agent, wann er die gewünschte Seite gefunden hat.
Zur Entwicklung solcher Agenten werden folgende Techniken und Methoden benötigt
werden:
- Textklassifikation
- Maschinelles Lernen
- Planen
- Wissensrepräsentation
- HTML/HTTP/Java-Programmierung
Die fertigen Agenten sollen experimentell evaluiert werden und evtl. auf dem WWW der
Allgemeinheit zur Verfügung gestellt werden.
PG-Teilnahmevoraussetzungen
Minimalziel
- Entwurf und Implementierung einer Agenten-Shell
(inklusive Planer und Textklassifikator)
- Implementierung eines funktionsfähigen Agenten
Literatur:
- 1
- Michael J. Wooldridge und Nicholas R. Jennings.
Intelligent
Agents: Theory and Practice.
Knowledge Engineering Review, 10(2):115-152, 1995.
- 2
-
Nicholas R. Jennings und Michael J. Wooldridge.
Software Agents.
IEE Review, 42(1):17-21, 1996.
- 3
-
Oren Etzioni und Daniel Weld.
A
Softbot-Based Interface to the Internet.
Communications of the ACM (CACM), 37(7):72-76, 1994.
- 4
-
Thorsten Joachims,
Text
Categorization with Support Vector Machines: Learning with Many Relevant Features.
Universität Dortmund, LS VIII-Report, Nr. 23, 1997.
- 5
-
Jonathan Shakes, Marc Langheinrich und Oren Etzioni.
Dynamic
Reference Sifting: A Case Study in the Homepage Domain.
In Proceedings of the Sixth International World Wide Web Conference (WWW6),
Seiten 189-200, 1997.
- 6
-
Jude Shavlik und Tina Eliassi-Rad.
Intelligent
Agents for Web-based Tasks: An Advice-Taking Approach.
In Learning for Text Categorization, Papers from the AAAI-98 Workshop, Technical Report
WS-98-05, Seiten 63-70, Menlo Park, CA, USA, 1998. AAAI Press.
- 7
-
José Luis Ambite und Craig A. Knoblock.
Planning
by Rewritting: Efficiently Generating High-Quality Plans.
In Proceedings of the Fourteenth National Conference on Artificial Intelligence (AAAI-97),
Providence, Rhode Island, 1997.
- 8
-
Naveen Ashish, Craig A. Knoblock und Alon Levy.
Information
Gathering Plans With Sensing Actions.
In Proceedings of the Fourth European Conference on Planing (ECP-97),
Toulouse, France, 1997.
- 9
-
C.A. Knoblock, S. Minton, J.L. Ambite, N. Ashish, P. Jay Modi, I. Muslea, A.G. Philpot und S. Tejada.
Modeling Web Sources
for Information Integration.
In Proceedings of the Fifteenth National Conference on Artificial Intelligence (AAAI-98),
Seiten 211-218, Madison, WI, USA, 1998.
- 10
-
T. Joachims, D. Freitag und T. Mitchell,
WebWatcher:
A Tour Guide for the World Wide Web.
Proceedings of International Joint Conference on Artificial Intelligence (IJCAI), 1997.
- 11
-
T. Joachims und D. Mlademic, Browsing-Assistenten, Tour Guides und adaptive WWW-Server.
Künstliche Intelligenz, Vol. 4, 1998.
Weitere Informationsquellen
Letzte Änderung: Thorsten Joachims, Freitag, 20.11.1998, 18:05 Uhr
Letzte Änderung: Ralf Klinkenberg, Dienstag, 15.06.1999, 14:00 Uhr
