
?
INFORMATION SOCIETIES TECHNOLOGY
(IST)
PROGRAMME
Contract for:
Shared-cost RTD
Annex 1 - ?Description of Work?
Project acronym: MiningMart
Project full title: Enabling End-User Datawarehouse Mining
Contract no.: 11993
Related to other Contract no.: IST-2001-35479
Date of preparation of Annex 1: 29.May 2002
Table of Contents
1. Project Summary....................................................................................................................................... 4
Objectives................................................................................................................................................. 4
Description of work................................................................................................................................... 4
Milestones and expected results.............................................................................................................. 4
2. Project? Objectives.................................................................................................................................... 5
2.1 The goal............................................................................................................................................... 5
2.2 The Objectives.................................................................................................................................... 5
2.3 Operational Goals and Techniques to Achieve Them........................................................................ 6
2.4 Baseline............................................................................................................................................... 7
2.5 Measure of Success............................................................................................................................ 7
The other workpackages and deliverables do not serve the operational goals of the research, but are for information dissemination and for technology implementation...................................................................................... 10
3. Participant List....................................................................................................................................... 11
4. Contribution to Programme Objectives................................................................................................. 12
5. Innovation............................................................................................................................................... 14
6. Community Added Value....................................................................................................................... 15
7. Contribution to Community Social Objectives..................................................................................... 16
8. Economic Development and S&T Prospects......................................................................................... 17
9. Workplan................................................................................................................................................. 20
9.1 General Description.......................................................................................................................... 20
9.2 Workpackage List............................................................................................................................. 21
9.3 Workpackage Descriptions............................................................................................................... 22
9.4 Deliverables List............................................................................................................................... 44
9.5 Project Planning and Time Table...................................................................................................... 46
9.6 Graphical Presentation of Project Components............................................................................... 47
9.7 Project Management......................................................................................................................... 48
An environment for the support of knowledge discovery from databases (KDDSE) will be developed that provides decision-makers with advanced knowledge extraction from large distributed data sets. New techniques for selecting and constructing features on the basis of given data will be developed. For instance, ways of handling time (time series, relations of time intervals, validity of discovered rules), discovering hidden variables, and detecting interdependencies among features will be investigated. The techniques ease knowledge discovery where currently most time is spent in pre-processing. Domain knowledge will be exploited by data mining. This will enhance the quality of data mining results. A case-base of discovery tasks together with the required pre-processing techniques will offer an adaptive interface to the KDDSE. This will speed-up similar applications of knowledge discovery and make the KDDSE self-improving.
The scientific research for enabling end-users to gain knowledge from databases and data warehouses is organized? in two themes: a meta-model and multi-strategy learning. The meta-data offer constraints for pre-processing and pairing business tasks with algorithms (WP1, WP8, WP10, WP 18).? A deep analysis of feature selection, sampling, transformation and mining operators is developed. Multi-strategy learning systematically explores the combinations and (automatic) parameter setting of diverse learning operators for pre-processing, particularly for feature constructions and selection (WP4, WP13, WP14). Handling of multi-relational data (WP15), time phenomena (WP3), and the inclusion of domain knowledge (WP5) enhance discovery.
The support of data mining in data warehouses is based on databases directly. The model for the description of data mining cases (the meta data) becomes operational through a compiler that transforms mining cases into SQL statements or calls to mining tools that directly access the database (WP8, WP12). Scientific and technological efforts yield a case-base of best-practice discovery (WP10) that can be used by users of the environment and is published in the internet for an international ?representation race?(WP9).
Applications guarantee that research and technology focus on the most challenging and demanded issues. The data warehouse provided by SwissLife and a set of data mining applications from PSN and TILAB evaluate the transferability of results.
Milestone 1 delivers a first prototype of a KDD support environment, applications being set up and their demands being specified. The definition of the meta-language provides the basis for further work.
Milestone 2 delivers user-driven data transformations and learning operators, both described by meta-data.
Milestone 3 provides a case-base together with human computer interfaces that allow to set up or adapt data mining cases. An on-line service is established in the Internet.
The goal of this project is that knowledge discovery becomes a powerful, but not difficult, query facility for very large databases. End users should ideally be able to directly query large and heterogeneous data sets in their own language. Such queries are typically application-driven. For example, data analysis should provide answers for the optimisation of mailing campaigns, for the analysis of warranty cases in order to improve production quality and for the discovery of business trends. An innovative approach to this goal is to provide end-users with a case-base of excellently solved discovery tasks. The users may run an application by simply referring to a case. Easing the access to knowledge hidden in large data sets will enable SMEs to benefit from their data collections. Consulting customers who want to optimize their business processes on the basis of their data bases is supported.
In order to make knowledge discovery a powerful and easy query facility for very large databases, the current tools need to be enhanced in the following ways:
? Supporting advanced pre-processing of data
? Supporting the view of the end-user by the case base
? Reducing the number of trials for each discovery task
? Decreasing the amount of data to be kept within the data mining procedures.
It is well known that data representation strongly influences the quality and utility of the analysis results, and that problem reformulation is a core technique in problem solving. Improving the quality of data improves the quality of the mining results. Extensive documentation on the importance of non-algorithmic issues in real-world applications are reported. The ?no free lunch theorem? in essence tells us that choosing a not so well-suited mining algorithm can be compensated by a sophisticated pre-processing method, or, the other way around, that excellent results of data mining frequently rely on the appropriate pre-processing of the data. However, the task of reformulating data is difficult and demands high skills. As a result, knowledge discovery in large databases is not used by the common people, but by a few highly skilled power users. Developing more sophisticated pre-processing operators will make KDD more effective.
The formulation of discovery tasks in terms of business applications bridges the gap between the technologies and the users. Since end-users cannot solve the difficult task of reformulation in order to get their desired answer, they might wonder whether somebody else had a similar question and got the answer. The project will develop a case-base of excellently solved discovery tasks. The tasks are described in terms of business applications. The cases serve as blueprints for further similar queries to similar data. The user need not try out all possible procedures but start with a most promising one.? This should reduce the number of trials to a large extent. The case-base thus offers a user-friendly interface to the best practice of knowledge discovery from very large and heterogenous data sets.
It is not feasible to extract all data in a warehouse for pre-processing when only a very small percentage of the data is actually needed for the discovery task at hand. In many applications the computer used for data mining is different from the one hosting the data warehouse. It may also be impossible to copy all of the data warehouse to the data mining computer due to Ethernet overload or insufficient disk-space at the mining station. Hence, discovering knowledge in very large data sets requires a new work-share between the datawarehouses and the discovery operators.
To overcome the shortcomings of current knowledge discovery, the proposed work addresses the following four closely related objectives:
1) Create user-friendly access to data mining for the non-expert user through:
? providing advanced, partially automated support for pre-processing,
? pairing data with clever pre-processing and analysis methods,
? creating an (Internet) case-base of pre-processing and analysis tasks for re-use.
Meta data describing data formats, pre-processing operators and analysis algorithms will be employed to guide the user through the knowledge discovery task. For example, if the user selects an analysis method that can only process discrete variables, but selects a table containing continuous data to be analysed, then he will be prompted to select a discretization operator. One focus of the research conducted within this project will be to determine the extent to which such automated support can be given during pre-processing. It can be expected that this process cannot be fully automated, especially when completely new, high level data mining questions are to be solved. Ideally, the system would evaluate all possible transformations in parallel, and propose the most successful sequence of pre-processing steps to the user. This "representation race" is, however, computationally infeasible. One objective of the proposal is to allow each user to store entire chains of pre-processing and analysis steps for later re-use in a case-base (for example, a case of pre-processing for mailing-actions, or a case of pre-processing for monthly business reports). It is conceivable that completely new tasks will be solved by highly trained specialists who could store their work over the Internet in a centralized case-base to make such new cases accessible to less advanced users. This way, world-wide experience with knowledge discovery can be systematically stored such that the user's knowledge about the data, the mining-task and the connection between them is preserved. The case-base could even be mined for knowledge about knowledge discovery.
2) Speed up the discovery process by
? reducing the number and complexity of trial and error pre-processing and analysis cycles. ?The case-base of pre-processing and analysis tasks described within the first objective will not only assist the inexperienced user through the exploitation of experienced guidance from past successful applications, but also allow any user to improve his skill for future discovery tasks by learning from the best-practice discovery cases.
? allowing the re-use of pre-defined building blocks and entire analysis tasks. Some analysis tasks are repeated regularly. A case base of stored discovery tasks will free the user from specifying the same steps repeatedly.?
3) Minimize the amount of data that is kept within the data mining operators. This objective will be achieved by executing as much of the pre-processing as possible within the data warehouse. It is not feasible to extract all data in a warehouse for pre-processing when only a very small percentage of the data is actually needed for or applicable to the data mining task at hand. In many applications the computer used for data mining is different from the one hosting the DBMS. It may also be impossible to copy all of the data warehouse data from the DBMS to the data mining computer due to Ethernet overload or insufficient disk-space at the mining station. The methods developed within this project will allow maximal utilization of database technology. Pre-processing operations that can be efficiently executed within the database will be executed within the database. It can also be expected that achievement of this objective will? speed up the discovery task (objective 3).
4) Improve the quality of data mining results by improving the quality of data. Transforming raw data into a high-value basis for discovery is a time-consuming and tedious task, but it is also the most important step in the knowledge discovery cycle and a particular challenge in real world applications. In this project, a set of transformation tools/operators to ease this task will be developed. Machine learning operators are not restricted to the data mining step within knowledge discovery. They can well be seen as pre-processing operators that summarize, discretize, and enhance given data. However, this view offers a variety of learning tasks that are not as well investigated as are learning classifiers. For instance, an important task is to change the level of detail of the data by means of aggregation operators, according to the task and/or the algorithm used. These tools improve the quality of data with respect to redundancy and noise, they assist the user in selecting appropriate samples, in discretizing numeric data and provide means for the reduction of the dimensionality of data for further processing. Making data transformations available includes the development of an SQL query generator for given data transformations and the execution of SQL queries for querying the database.
Traditional approaches fail to release the knowledge from the masses of available data. Two technologies are emerging for the rescue: (1) data warehousing for on-line analysis of data and verification of hypotheses and (2) knowledge discovery in databases (KDD) for discovering knowledge which is hidden in the data. Practical experience with these techniques have proven their value. However, it is also apparent that using a data warehouse for decision support or applying tools for knowledge discovery are difficult and time-consuming tasks. The actual data mining step is well understood and efficient tools exist, but the pairing of data with algorithms and the clever pre-processing of the data are still a matter of trial and error. If we inspect real-world applications of knowledge discovery, we realize that up to 80% of the efforts are spent on finding an appropriate transformation of the given data, finding appropriate sampling of the data, and specifying the proper target of data mining. Interest in this European project comes from the experience with knowledge discovery in very large relational databases: most of our efforts concern the transformation of data into a form which is appropriate for data mining. Especially time sequences, time intervals, and relations between time intervals belong to the hardest issues. Even if the data are transformed and a learning algorithm is selected, the tuning of the algorithm?s parameters currently ask for many trials. These issues require a multi-strategy approach, where one learning task delivers input to the next one. This representation change, however, has not yet received enough attention in the scientific community which still concentrates on the learning algorithms themselves.
Corresponding to the overall goal of the project, the criterion is:
By the end of the project, some discovery
tasks, for which entries in the case-base exist,
can be solved with only 20 % of the time for pre-processing,
where the time for the data mining step remains the same as before the project.
This criterion is made operational corresponding to the objectives stated in section 2.3 within workpackage 17.? The system MiningMart will be installed for real end-users of industrial partners (SwissLife and TILAB). They will use the system for their regular jobs of decision-making and reporting. At least one of the discovery tasks, the users want to perform, has been set-up by project members before, so that meta-data about the task and a solution exists. In this case, the end-users can use the case-base of best-practice. This setting is used for in-depth evaluation.
? Measure to creating user-friendly access to data mining for non-expert users:
End-users report on their experience with using the MiningMart: is it easy to use, transparent, and supportive? Is the flow of control natural to the users? Can they make good use of the results? How do they assess the results?
End-users compare their task performance with and without the MiningMart:
are they faster when using the system? Can they do more when using the system?
? Speed-up the discovery process:
The comparison of discovery with the
accomplished MiningMart system and without it will be performed for the SwissLife
application. In WP 6, an anonymous datawarehouse together with discovery tasks
is delivered to all partners. Pre-processing operators are applied to solve
the task, of course without the support of the MiningMart system which does
not yet exist at this point in time. The time for finding the appropriate data
transformations will be measured.? The pre-processing will then be enhanced
by the methods of WP3, WP4,? WP13, WP14, and WP16. The end-users at SwissLife,
a business controller and a member of the marketing division, will use the MiningMart
system which then includes the enhanced pre-processing. Their time for solving
the same task will also be measured. We aim at a reduction to only 20% of the
original pre-processing time.
? Minimize the amount of data kept within KDDSE:
Current KDD systems have to load all data for data mining. This is not feasible. WP2 will investigate methods that allow for a new work-share between datawarehouse and KDD operators with respect to data management. Further on, WP15 will develop a new interaction concerning multi-relational data. The aim is to perform extensive processes directly within the datawarehouse. A clear and operational measure of success is whether a huge datawarehouse can be handled by the MiningMart.
?
Improve the quality of mining by improving
the quality of data:
The main measure for the quality of data mining
results is their accuracy on test data. WP3 and WP4 as well as WP 14 will deliver
comparisons of mining with and without the pre-processing methods developed
in terms of precise figures. The international contest? (?representation race?)?
(WP20) will deliver additional test results.
This general evaluation of success can be made operational for on-going quality assurance. Actually, the high number of workpackages is meant to ease the monitoring of the project. Each workpackage is a move towards one of the goals, each of its deliverables is a step. Hence, as long as every deliverable is in fact delivered, we know that we shall approach our goal. Here we present the paths to achieve good results for each of the success criteria just shown. They will be used? as a check-list for progress monitoring.
? Measures to creating a user-friendly access to data mining for non-expert users:
? Milestone 1: The start-up KDDSE is delivered to all project partners, so that project members as the first users can assess whether it is user-friendly or not, and propose enhancements. WP5 prepares the ground for WP19 in investigating means to incorporate knowledge about the application ? as is viewed by application people ? can be used for discovery.
? Milestone 2: WP8 delivers operators that should ease pre-processing.? A meta model allows to specify a data mining case together with the given data and the domain concepts involved.
WP 19 is a first attempt to express discovery tasks and goals in terms of (business) applications. If the transfer to all partners succeeds, i.e. partners want to apply the meta models for their own applications, it is a clear indication of success.
? Milestone 3: WP10 delivers the case-base of pre-processings, i.e. the best-practice of pre-processing which can be used by not so experienced user. Its success becomes apparent only by users? assessments (WP17). The same holds for WP12 which deliver the final human-computer interface. The final evaluation is done in WP17 as described above.
? Speed-up the discovery process:
? Milestone 1: The basis of all further evaluations is the delivery of a real (anonymized) datawarehouse by WP6. The basis of further work on pre-processing operators is the specification delivered by WP1. Indirectly, the specification will describe more detailed success criteria as found important because of applications? requirements. The first advanced pre-processing (those handling time or sequences) will already be proposed at this milestone.
? Milestone 2: WP4 supports the tuning of parameters of mining algorithms. Clearly, the time used for determining optimal parameter settings will be measured and compared to the time necessary without the new technique. In order to ease monitoring of progress, one deliverable? is due early on (B+12).
? Milestone 3: WP13, WP14 and WP16 deliver advanced pre-processing operators. They are evaluated with respect to speed-up as well as accuracy of learning results.
? Minimize the amount of data kept within KDD procedures:
? Milestone 1: First results will be already available at B+6 when WP2 will have investigated new approaches to work-share between database (datawarehouse) and KDDSE.
? Milestone 2: WP15 will extend the approach from WP2 to multi-relational data. The capability to perform hypothesis testing directly on a database or datawarehouse is a clear success. If this would fail, the project has still time to recover.
? Milestone 3: WP17 evaluates clearly how many records are to be stored within the KDDSE and how many can be ignored or handled by the database or datawarehouse.
? Improve the quality of mining by improving the quality of data:
? Milestone 1: First results comparing combinations of pre-processing and mining are delivered by WP3. The improvement of accuracy? by? different representations of time or sequences can thus be measured.
? Milestone 2: WP4 will compare average accuracy achieved with and without tuning of parameters. Of course, the success is to move beyond the initial average accuracy. WP15 will compare combinations of pre-processing and mining of multi-relational data. The improvement of accuracy is one measure of success. However, if ? for some combinations ? it can be shown that no improvement can be achieved, this is also a very valuable result!
? Milestone 3: WP14 will compare feature selection and construction operators. The ones that improve accuracy of learning results will be made available to customers of the MiningMart. The success criterion is the increase of accuracy . WP16 provides pre-processing operators for discretization and grouping. WP18 delivers conditions which characterize the applicability conditions of operators. These are meant to serve as a prediction of successful discovery as well as a ?pruning? criterion where which operator does not make sense. It can be tested whether the conditions cover successful operator application of the project and do not cover unsuccessful ones. The international contest in the internet will deliver additional test results (WP20).
Supporting advanced pre-processing means that a set of operators for intelligent data transformations is modeled within the framework of the MiningMart. The MiningMart consortium has delivered some operators. However, it turned out that the discretization operators are not really sufficient for handling all cases that the project would like to handle. The feature generation and selection is a central issue in intelligent pre-processing. UEP has worked on intelligent pre-processing operators and will deliver additional operators. Their experience in winning KDD competitions by intelligent pre-processing will enlarge the scope of pre-processing when integrated into the MiningMart framework, namely being integrated into the meta-model by operator descriptions and by operator implementations that directly access databases. Also UEP will report on the usability of the meta-model for describing new operators.
The speed up of discovery tasks by the re-use of existing cases can best be verified when a new discovery task is set up? by somebody who has not participated in the project internal discussions. NIT offers the exciting opportunity to use the project results for a new discovery task already within the project duration. From this evaluation we expect feedback that can enhance the project results. The same holds for the objective of improving data mining by improving the quality of data. The new task of NIT will give us a clear result whether, in fact, our expectation is correct, that the pre-processing as offered by MiningMart cases improves the data mining results. NIT will use the meta-model to investigate their customers and will report on the advantages and disadvantages of the current project results. The Mining Mart project will then use the feedback to adjust its work. This early feedback promises a much stronger position with respect to usability? questions than are possible when the first application? of the MiningMart to a new task from outside the project occurs only after the project duration. Last but not least, NIT provides the MiningMart with a new case.
List of Participants
Participant Role
Participant number
Participant name
Participant short name
Country
Status*
Date enter project
Date exit project
C
1
University Dortmund
UniDo
Germany
C
P
2
University Piemonte Orientale ?Amedeo Avogadro?
DISTA
Italy
P
P
3
Perot Systems Netherland
PSN
Netherlands
P
P
4
Dialogis
Dialogis
Germany
P
31.05.01
P
5
SwissLife
SwissLife
Switzerland
P
P
6
Telecomunicazione Italia Laboratori? S.p.A.
TILab
Italy
P
P
7
FhG/GMD Institute for Autonomous intelligent Systems
AiS
Germany
P
1.3.02
P
8
Univerity of Economics, Prague
UEP
Czech Republic
P
1.3.02
P
9
National Institute of Telecommunications
NIT
Poland
P
1.3.02
*C = Co-ordinator (or use C-F and C-S if financial and scientific co-ordinator roles are separate)
? P - Principal contractor
?A - Assistant contractor
This proposal contributes to the thematic IST programme objective by building a user-friendly knowledge discovery tool for the information society. The international character of the proposed project and the participation of two SMEs complies well with the outlined horizontal programmes.
Knowledge discovery from databases (KDD) is widely recognized as the technology for the 21st century that enables people to gain insights from the vast amount of data collected world-wide. Data warehouse technology helps collect and handle such huge masses of data, but only KDD (and possibly OLAP) offer the tools and procedures to turn these data into usable knowledge. Data mining, as the core step within the KDD process, allows the non-technical user to formulate such high level queries as:
? output the most similar records
? identify exceptional records
? determine the most influential factors
? output the 10000 most likely responders to my next mailing campaign.
Current industrial strength data mining tools allow the formulation of a multitude of similar queries to direct analysis. Two drawbacks of the present state-of-the-art tools is that despite visual programming user interfaces, users must be KDD specialists and spend most of their time preparing the data for analysis. There is also relatively little support from the data mining tool in this tedious process. While this is accepted by early adopters and during initial data mining projects, most users demand that previous pre-processing tasks are re-usable and that semi-automated support for new tasks is available. This is the aim of the proposed project. Solving these user-support problems is necessary before KDD can be fully effective and accessible to the broader group of users who could benefit from data mining technology.
This project could be considered as part of a cross-program cluster (CPC) because its results will be relevant to several key actions. The project is related to several action lines, the "center of gravity" being item 3 of Key Action IV.3 (technologies and engineering software, systems and services, including high-quality statistics): methods and tools for intelligence and knowledge sharing. The result of this project is a technique enabling the end user to use data mining (i.e., advanced statistics) and some OLAP functionality within a data warehouse environment (very-large scale data). We intend to build an environment with an advanced graphical user interface that enables the user to easily define new pre-processing and analysis tasks via case retrieval from previously defined pre-processing tasks. This project contributes to CPA4: New indicators and statistical methods by developing and applying an advanced user-friendly data mining tool for improving data quality, knowledge extraction, and statistical modelling. The tool will contribute to the dissemination of information by enabling a broader group of users to run data mining analyses without the help of experts. The machine will further support the user through case adaptation and optimization. Meta-data about the data to be analyzed (obtained from an information repository), the data warehouse, the data mining tools, and the pre-processing operations will be employed to guide the user while defining new tasks. The primary goal is the easy adaptation of existing pre-processing cases to new applications.
Other related Key Actions are:
? IV.3.4: information management methods. The project builds an environment where mass-storage and processing of the data is done within the data warehouse. Therefore, existing data warehouse technology is used to enable end-users to conduct data mining on very large data sets.
? II.1.2 Corporate knowledge management. A tool for representing and capturing (distributed) organizational knowledge in working environments will be developed. The project is based on existing data warehouse technology, which solves the issues of the distributed and heterogeneous nature of available data and their repositories.
? Future priority action of III.5 Information Access, Filtering, Analysis and Handling: Information filtering and agents. Data mining technology is a core technology for information filtering and analysis, and hence,? contributes to this future priority action.
? I.4.1 Systems enhancing the efficiency and user-friendliness of administrations. The system developed during this project can be seen as an advanced multimedia integrated system for administrations and other public bodies, to improve businesses' and citizen's access to information. Multi-media data can be analyzed through a change in representation. Pictures are usually represented for mining by large feature vectors, spatial-data (geographic information) by multi-relational neighborhood and distance relations, and texts for WWW- and text-mining by large feature vectors (word-lists). Pre-processing and data mining are enabling techniques, even though this is not explicitly addressed in the project.
The proposal builds on the insight that current approaches for achieving the objectives described above tend to ignore theoretical results that have proven that no algorithm can claim to be systematically better than any other on every problem (Wolpert?s ?no free lunch theorem?), and that nobody has yet been able to identify reliable rules predicting when one algorithm should be superior to others. The innovation of this proposal is to combine the two factors that are known to be able to solve nearly any challenge: human experts and sheer numbers!
A constraint based graphical user interface utilizing meta-data shall guide users through the knowledge discovery task. The highest possible degree of automation for this process will be the aim of this project. However, as reasoned above, it cannot be expected that the user simply asks a high level question and selects a data set to be analyzed and everything else is done automatically. In particular, the task of proper transformation of the given data into a format that can be successfully analysed by the available algorithms is difficult. As discussed above, testing of all possible approaches through a "representation race" is currently not practical because the required computational power is not accessible for any single user. However, if the nearly infinite resources of the Internet are utilised, then such a race may be reasonable. The idea is that a searchable case-base of solutions to discovery tasks is made available on a web-server. Users that have access to this facility can search the case-base for suitable solutions to their task at hand. If no proper solution is found, the task could be posted as a new challenge. Knowledge discovery experts working alone or in groups could tackle the problem, and insert a solution into the case-base. Large clusters of computers could also be combined to find the right answer through sheer computational power, similar to clusters of computers that are built to find new largest known prime numbers.
Why would people participate in such a competition, and post their solution in the case base? Several motivations are conceivable: financial rewards, acknowledgement ("Miner of the Month"), and most importantly, access to the case-base itself. Relevant research issues are how to efficiently store results in the case-base, and how to maintain and query the case-base. Data mining technology could be used to maintain and update the case-base, to create ratings, and to learn how to adapt retrieved cases.
The goal of building up an environment for pre-processing that supports the user in taking advantage of its own data will reduce the time and cost for data mining. In this way, also smaller companies, specifically SMEs, could profit from this methodology, which, in the upcoming information society, might prove vital for their survival and competitiveness. For this reason, the proposed project is in line with several priorities and policies of the EC: to enhance the user-friendliness of information tools, to empowering small companies (SMEs), by giving them the possibility of exploiting their own past experience hidden in historical data, and to guarantee to a larger community the keys to important information resources, favoring thus the development of a fair access? to the information society.
Furthermore, a side effect of the project will be a kind of standardization of the data mining process, enhancing transferability, re-use and increased possibility of data and tools sharing. The effect? will be an increased European awareness of the value of shared information technologies, and a global increase in the amount and quality of the knowledge extracted from data. In fact, following standardized data pre-processing methodologies, data from various countries could be handled cooperatively. This aspect is particularly important for those issues in which all European countries are interested and systematically collect data, such as environment monitoring and ecosystem preservation.
In order to attain the goal of the project, European partnership is necessary to achieve a critical human and financial mass. Moreover, different competencies are to be integrated. Specifically, academic teams master methodologies but usually do not dispose of large datawarehouses, nor have the resources to engineer their algorithms for use by a wide community of non specialist users. Industrial companies have the data, and software companies the human resources to make a product out of a prototype. Then, partners from the threes components nicely complement each other.
Second, it is not unreasonable to believe that the gradual diffusion of data mining needs to a large number of smaller companies and to public organisations will increase the opening of new qualified jobs, contributing thus directly to increase employment.
Third, data mining research and the market for data mining tools is dominated by North-American science and commerce. It is very hard to find a niche for European contributions and expertise. However, the customers of data mining within Europe still need consulting and guidance. Here, European expertise can be marketed. Similar to the experience with Linux, where the system is for free but accompanying consulting can be marketed, we perceive the MiningMart a free archive that supports data mining consulting.
Data mining research and the market for data mining tools is dominated by North-American science and commerce. It is very hard to find a niche for European contributions and expertise. However, the customers of data mining within Europe still need consulting and guidance. Here, European expertise can be marketed. Similar to the experience with Linux, where the system is for free but accompanying consulting can be marketed, we perceive the MiningMart a free archive that supports data mining consulting.
The consortium as a whole will market its results through a Workshop (WP11) and the Internet server publishing the meta-data of successful discovery cases.
The software partners, AiS and PSN, have particular exploitation plans.
Over the years PSN?s focus has shifted slightly from data mining tool sales to large consulting projects in the area.? With this shift, the realisation came that large amounts of preprocessing were necessary before actual data mining tools could be applied.? Up to now this preprocessing phase has depended largely on available knowledge about database management and to a large degree on gut feeling about the problem domain.? A proper structuring or automation of this task was lacking.?
The results from this project will have the following benefits for PSN:
? Reduction of the initial phase of preprocessing in a data mining project, which currently may be up to 80% of the overall time spent on the project.? This reduction in overall time, and thus in total costs of the project, will make future projects more attractive and easier to sell.
? Widening of scope of a data mining project.? Due to a more efficient preprocessing phase, there is more room to examine alternative approaches which would otherwise be a luxury, given a fixed budget.
? Increase in quality of the results.? Because of a better structured and automated preprocessing phase, suggestions can be tried which would otherwise be overlooked.? Given more and better suggestions, the analysis phase will be improved which again results in the production of models with higher quality and accuracy.?
? Decrease of training required for consultants.? Due to an increased level of automation, and better guidelines, less training of consultants is necessary and more people with different backgrounds can be put on data mining projects.? In the current situation at PSN more data mining projects have been initiated than can currently be performed by the data mining team.
? Better convincing value proposition during the acquisition of new projects.? Because of the relative complexity and novelty of the data mining technology, PSN has to rely on free pilots and workshops in order to convince new customers.? During such short pilots a better impression can be made if the laborious preprocessing phase is automated and thus skipped rapidly.? We can then focus more of the actual analysis which has to convince the customer in the end.
PSN expects that all of these benefits will have a serious effect on the sales of data mining projects for PSN. Not only will improved pre-processing make projects cheaper, and thus easier to sell, but it will so make them more successful.? The success and quality of such projects has proven to produce new spin-offs, not just at the current customer, but also at potential new customers.? Because of the large attention for data mining in the technical media, success stories are a good way of attracting new business.
In specific, PSN intends to exploit the results of this project both with current and future data mining projects.? The preprocessing tool will be an excellent complement to the current data mining tools that we market.? These data mining tools currently support the preprocessing phase only in a minimal form, and we have to rely on functionality provided by standard RDBMSs.? This has been a complaint with current customers, which can now be solved by marketing a package of tools.? The results stemming from the more research oriented workpackages will be used as internal guidelines and methodologies. Through these documents, less trained personnel will be able to implement data mining projects more efficiently and with a higher quality of results. The results will be exploited not just on the Dutch market through PSN, but on a European and worldwide scale through its owner Perot Systems, were PSN is acting as the official Competence Centre for data mining.
Institute for Autonomous intelligent Systems (AiS) has a large and active knowledge discovery research group. Projects focus on the application of data mining to spatial data and on multi-media and text-mining. In both areas AiS has a substantial number of on-going national and international projects. Additionally, AiS will coordinate the KDNet? Knowledge Discovery Network of Excellence (currently under negotiation).?
To understand AiS? exploitation plan one has to keep in mind? that AiS is currently in a process of merger with the German Fraunhofer Gesellschaft, which is one of the largest and most succesful European institutions for applied research. As a consequence AiS, while maintaining its position in international research, will have to build up structures that allow for rapid and successful transfer of research to industry. This will lead to an increase in its third-party funding from industry, both in proportion and in absolute numbers. That AiS is in a excellent position to do this is demonstrated by the fact that it already increased its third-party funding from 220 kEuro in 1999 to (estimated) 600 kEuro in 2001. With more than a dozen researchers and software developers, as well as a proven track record in project management,? it has the appropriate skill-set to cope with this challenge.
It is not AiS? primary goal to get large revenues from selling or licensing software tools.? The last years have shown that many data mining startups have evolved away from such a business model. The GNU data mining suite WEKA and the R statistical analysis package offer now zero-cost solutions for the researcher and expert user. On the other side, big and well-established companies such as Oracle (Darwin), SAS, SPSS (Clementine) or IBM offer data-mining solutions (often acquired by buying smaller companies), offering stiff competition to smaller companies that want to enter the market. In that situation it seems likely that small companies only survive if they enter niche markets, offering vertical solutions (such as PharmaDM), customizing existing tools, or adding value to the distribution of tools by offering high-quality consultancy services.
Especially the latter is a business model that suits well the skill-sets of AiS Knowledge Discovery Team. It has a long tradition in building software tools (among others the first versions of the Kepler system used in Mining Mart). It also has broad methodological experience in fields ranging from Bayesian Markov Chain Monte Carlo to Inductive Logic Programming and Support Vector Machines, and has worked in application areas such as credit scoring, process optimization, census data analysis, site selection.
To successfully combine basic with applied research, it is planned to built up a unit that applies Data Mining technologies in industrial cooperations. The Mining Marts software will be an important addition to the suite of tools already available at AiS. The task of pre-processing data for analysis is well known as the most time consuming task in the entire knowledge discovery process. Hence, these tools will have an immediate and maintained role in current and future research and applied projects. This helps to maintain the software for a longer period and to get synergies.
AiS develops the SPIN! Data mining platform for the analysis of spatial data. This software is further developed in a national project ?Kogiplan?.? In this project, the results of SPIN! are combined with optimization algorithms and applied to commercially highly relevant site selection problems. This system already contains a version of? a data extraction and transformation. However, its? functionality is reduced compared to Mining Mart. Combining both project?s results leads to important synergies. Mining Mart data extraction tools will be an important addition to that system, greatly enhancing its exploitation potential both for new research and commercial projects.
One of the core areas where AiS will become active is statistical offices.? The UK census schema comprises about 90 tables with ~8000 attributes. If geographic layers are added, the number of tables is further increased. The complexity of queries increases since spatial joins, linking geographic data, are required.? A powerful, easy to use data access and extraction tool would be a boon for census data analysts.
AiS will use its position as co-ordinator of KDNet (currently under negotiation) to disseminate and exploit the scientific results of the project. KDNet offers various possibilities to do this:
The Mining Mart project schedule allows timely dissimination of its results by those KDNet activities.
Private life insurance as well as management of company pension systems are markets in Europe with strong future impact due to the expected demographic development. These markets are currently changing rapidly due to the deregulation of these markets all over Europe. Swiss Life is currently developing a data warehouse with customer information and is most interested in the opportunities that? assessing its contents will offer. The most prominent goals of Swiss Life in this respect are to make better and more economical use of the data in Swiss Life?s databases for better customer management, the development of new innovative life-insurance products based on improved individual risk-assessment and management, and better recognition as well as faster reaction to changes in the market. These goals hold especially for the management of company pension systems where a much broader product spectrum exists for companies ranging from small (1-5 employees) to very large (several thousand employees of multi-national corporations, supported internationally by Swiss Life), than in the private person life-insurance market.? Swiss Life believes that these goals can only be achieved if the end user is empowered to directly conduct data mining analyses on the data warehouse which is the aim of this project. In a longer perspective the results of the project will be distributed by Swiss Life, Zurich, to other branches of Swiss Life, e.g. Swiss Life Germany where a data warehouse is currently developed, Swiss Life France to support an integrated marketing of its life insurance branch and its new health insurance branch.
Swiss Life will also promote the project results through scientific and educational activities: machine learning, KDD and insurance mathematics courses will be held at the University Konstanz, Germany and? both University and ETH Zurich, Switzerland. Results will also be distributed to the "Meta-data for Datawarehouses" user-group to be established in the Swiss national research project SMART.
It is observed that European companies ask for computer scientists with a special training in data mining and knowledge discovery. Only a few universities teach machine learning and knowledge discovery regularly. The academic partners of this project are among them. Their courses offer an opportunity to transfer the most advanced state of the art from research to the students. A more practice-oriented analysis of learning operators and manual preprocessing operators which will be developed by the project can be taught to students so that they not only know about algorithms and their computational complexity, but also about their combinability and effective use in knowledge discovery.
In addition, the internet service provided by the university of Dortmund will further strengthen the visibility of the partners as primary actors in the field of knowledge discovery.
The focus of each of the 20 workpackages can be loosely assigned to one of the abstract objectives of the project: research (as described in section 2.2), development of new technology, application and exploitation. The assignment must be loose due to the fact that some workpackages contribute to several of these objectives. However, it still helps to group the workpackages into these thematically related work groups:
? Research: Advanced pre-processing: workpackages 3, 4, 13, 14, 15, 16, and 18 investigate issues regarding advanced pre-processing operations and multi-strategy learning,
? Research: View of end-users: workpackages 5, 8, 18, and 19 construct the meta-data model of constraints for pre-processing operations and develop methods for matching of data mining algorithms with data for business tasks,
? New technology: workpackages 1, 2, 7, 9,10, and 12 develop the pre-processing environment
? Applications and exploitation: workpackages 6 and 17 reflect the application-oriented nature of the project, workpackages 11 and 17 ensure the proper exploitation of the project results, and
? Management: workpackage 20 is devoted to project management.
Three milestones serve in this project as synchronization points for all project partners. The first milestone after six months marks an unusually early milestone. The motivation is that after this milestone, all project partners can work with a common platform and that the specifications for subsequent work to be conducted within the project are well defined. This early synchronization reflects the highly integrative nature of the project. This way, all partners will have the chance to voice their input for further developments from the onset of the project. In contrast, projects with late synchronization points often lead to project results that are (technologically) not compatible with each other. The early milestone is feasible, since the basis of its primary deliverable, the data mining platform, is already available as a commercial KDDSE which only requires the tailoring towards the special needs of the project within WP2.
B1.
Workpackage list
Work-package
No
Workpackage title
Lead
contractor
No
Person-months
Start
month
End
month
Phase
Deliverable
No
WP 1
Pre-processing Operators Requirement Specification
DISTA
12
0
6
1
D1
WP 2
KDDSE
Dialogis
10
0
6
1
D2
WP 3
Learning about Time
UniDo
6
0
6
1
D3
WP 4
Informed Parameter Setting
DISTA
15.6
6
18
2
D4.1 D4.2 D4.3
WP 5
Domain knowledge
PSN
3
0
6
1
D5
WP 6
Data warehouse
Swiss Life
8
0
6
1
D6.1 D6.2
WP 7
Environment for Pre-processing
Dialogis
18
6
18
2
D7
WP 8
Meta-data for Manual and Learning Pre-processing
UniDo
24.5
6
18
2
D8
WP 9
Internet based interface to the case base
UniDo
9.5
22
36
2
D9
WP 10
Case-base of Pre-processing
PSN
9.5
18
36
3
D10
WP 11
Exploitation and Transfer of results
PSN
9.5
6
36
3
D11.0 D11.1 D11.2
WP 12
Interfaces to Meta-data driven Pre-processing
AiS
33
18
36
3
D12.1 D12.2 D12.3
WP 13
Clustering and Description Logic
SwissLife
3
18
30
3
D13
WP 14
Feature Construction and Selection
DISTA
32
18
36
3
D14.1 ? 14.5
WP 15
Multi-relational Data
PSN
17.5
6
18
2
D15.1 D15.2
WP 16
Discretization and Grouping
UEP
5
18
38
3
D16.1
D16.2
WP 17
Integration, Evaluation and Technology Implementation Plan
TILab
25
18
38
3
D17.0 ? 17.3
WP 18
Applicability Constraints on Learning Operators
UniDo
7.5
18
36
3
D18
WP 19
Problem Modeling
PSN
6
6
18
2
D19
WP 20
Project Management
UniDo
29.5
0
39
1-3
D 20.0 ? 20.5
TOTAL
284,1
Workpackage number :
WP1: Preprocessing Operators Requirement Specification
Start date or starting event:
Start +? 0
Participant number:
DISTA
SwissLife
TILab
Person-months per participant:
6
3
3
Objectives
In this workpackage we develop a specification of the preprocessing-operations needed to analyze our data warehouse. The collection of preprocessing requirements will serve as the unifying and organizing basis for all the other workpackages, which shall provide methods for satisfying each of them. Additionally to preprocessing operations such as data selection (sampling, segmentation, windowing, partitioning, ...) and? feature construction and selection, which already received some attention in the research community, we are concerned with an adequate handling of several N:M related tables, which are normally handled very inadequately by joins, and feature construction from historical data, which did not receive attention at all.
Description of work
Based on partners? previous experience, those aspects of data and algorithm selection and preparation that have proved to be most critical to the success in previous data mining activities will be identified, as well as the application context in which they arose. In particular, the issues of moving part of the data preparation and preprocessing to the original database will be dealt with. The work will be carried over by analyzing a set of both successful and unsuccessful previous data mining tasks, which will also serve for WP16.
Deliverables
A report specifying all the preprocessing operators needed to re-represent the data in a datawarehouse into a form suitable for specific mining tasks. The specification includes a classification of the operators, the identification of parameters to set, operator?s input and output, and a precise semantic specification in a form directly suitable to be executed on mass-storage data, e.g., as parametrized SQL-Macros. The report shall also contain an operator algebra, specifing? the possibilities of combining the operators in the preprocessing process. This report lays the base for the manual preprocessing WP7 and WP8,? and the automatization of pre-processing in WP3, WP4 and WP14.
Milestones and expected result
At Milestone 1 the introduction of precise syntactic and semantic definitions of preprocessing operators will have, as a results, a speed up of the mining task preparation phase. In fact, a library of operators, complete with applicability constraints, input and output, will help the user to quickly identify not only what kind of operations can be done on his/her data, but also the type and extent of information he/she needs to collect in order to perform the operation itself. Up to now, the decision about which steps to perform and in what sequence was done on a trial-and-error basis.
Workpackage number :
WP2: KDDSE
Start date or starting event:
Start +? 0
Participant number:
Dialogis
Person-months per participant:
10
Objectives
To develop and document the core pre-processing / data mining system: data warehouse access, proof-of-concept in-database pre-processing operators, enable project partners to write further pre-processing operators.
Description of work
Implementation of a JDBC interface of KDDSE for improved database / data warehouse access.
Modification of several existing in-core pre-processing operators currently available in data mining system (random sample, discretization, value mapping, and projection) to optionally operate directly inside the data base.
Specification and documentation of the programmers interface (plug-in interface) for pre-processing operators to enable the other partners to implement further operators. This will define a standard for further implementations.
Installation of the prototype at the research partner's cites.
Deliverables
D2.1: Plug-in API documentation
D2.2: Software libraries for database access
D2.3: Software libraries for in-database operators
Milestones? and expected result
The result of this workpackage will be a proof-of-concept integrated pre-processing and data mining system.
Milestone1: after 6 months functional JDBC interface, and deliverables D2.1-2.3
Workpackage number :
WP3: Learning about Time
Start date or starting event:
Start +? 0
Participant number:
UniDo
Person-months per participant:
6
Objectives
Investigating different phenomena of time (i.e., seasonal effects, sequences, cycles, time series, time intervals, relations between time intervals, changing concepts and concept drift, history) together with the known techniques from statistics and machine learning, that handle these phenomena.?
Description of work
From statistics and machine learning, the methods that explicitly handle time phenomena will be investigated. Moreover, the tricks of transforming time dependent data into a form that can be processed by methods that are incapable of explicitly handling time, will be described.
Meta-data for the selected methods will be written.
Deliverables
Report that presents known techniques for handling time phenomena and gives meta-data of those that are well-suited for knowledge discovery, and indicates the constraints that allow for simplification.
Milestones and expected result
At Milestone 1 a repertoire of methods for handling time phenomena will be available.
Workpackage number :
WP4: Informed Parameter Setting
Start date or starting event:
Start +? 6
Participant number:
DISTA
TILab
Person-months per participant:
12
3.6
Objectives
Goal of this workpackage is to provide a semi-automated procedure to help the user to define the parameters? values in a chosen algorithm, by exploiting user?s requirements on the output.
Description of work
When setting an algorithm/system to work, several parameters, both? categorical and numerical are usually to be defined. Often, a preliminary series of test runs is performed in order to find some sub-optimal parameter setting. This procedure may be time consuming. On the other hand, in most algorithms suitable to complex real-world applications, the relation between a parameter?s value and the output cannot be easily specified, not even qualitatively, because the interrelation between different parameters may mask the effect of each one.
On the other hand, the user, even though not knowing in advance the results of the mining, may nevertheless be able to explicitly specify some set of constraints on the desired output. For instance, in a segmentation task, he/she may want that customers with given characteristics mostly belong to the same group, and so on. The satisfaction of the constraints defined by the user can be codified into a function, which reflects the degree to which the constraints have been satisfied by the algorithm. This function can be automatically optimized with respect to the algorithm?s parameters. In order to introduce this step, constraint definition and algorithm?s run must be inserted into a closed loop, which the user is an integral part of. Two fundamental aspects differentiate this approach from the trial-and-error one: on the one hand, the loop is executed only one time, and, on the other, the parameter setting is determined automatically. Previous experience in using this approach in market segmentation tasks gave good results in terms of both speed up and user agreement on the quality of the results.
Deliverables
Deliverable D4 will consist of three part. In the first one, D4.1, the abstract description of the methodology will be presented, trying to capture those aspects that do not depend upon a specific data mining task.? An example of this task-independent part is the description of the loop into which the user and the algorithm are inserted, with the specification of the types of information that they should exchange.
The second part D4.2 will contain, for a sample of the algorithms/systems contained in the available toolbox, the specification of the parameters that can be tuned with this procedure, the types of meaningful constraints the user is allowed to specify, the method to encode these constraints, and, finally, the function to be optimized. The details of the overall process must be hidden from the user, who is only required, through a graphical interface, to specify the constraints.
Part three, D4.3, will be a program, implementing the complete procedure for one of the algorithms described in Part D4.2.
Milestones and expected result
At Milestone 2 the workpackage has three results, corresponding to the three parts fo Deliverable D4. After 3 months from the beginning, the definition of a common process scheme for a generic data mining task should be identified. After 6 months, the specific procedures for a sample of the algorithms must be ready. On the? basis of a comparative analysis of these procedures, one algorithm/system will be selected, and the corresponding procedure implemented.
Workpackage number :
WP5: Domain Knowledge
Start date or starting event:
Start +? 0
Participant number:
PSN
Person-months per participant:
3
Objectives
The objective of this workpackage is to examine what the influence of domain knowledge is on the contents of the data mining process.? We intend to examine what the effects of some of the constraints in the domain are on the necessary pre-processing operations.? The specific focus of this work package is on knowledge that describes the structure of the process the databases describing.? This is usually knowledge which is not yet written down formally in formal descriptions such as the database model.
Description of work
Possible classes of domain knowledge will be examined, and for each of these classes their usefulness for preprocessing will be established. On the one hand, background knowledge can be compiled into the set of examples. On the other hand, domain knowledge may restrict the search space by excluding areas which are known to be of no interest.
For each of these classes a set of possible preprocessing operations, selected from the total list of operations produced in WP1, will be listed.
Opportunities for incorporating available domain knowledge in the data warehouse of WP6 will be listed.
Deliverables
A report outlining the effects of domain knowledge on the preprocessing process.? The report lists possible sources of domain knowledge, and preprocessing operations associated with each of these.? The classes are exemplified by real-life cases.
Milestones and expected result
At Milestone 1 the state of the art in handling domain knowledge within KDD will be enhanced.
Workpackage number :
WP6: Data warehouse
Start date or starting event:
Start +? 0
Participant number:
SwissLife
TILab
Person-months per participant:
6
2
Objectives
The objectives of this workpackage is to provide a most interesting, but anonymous excerpt of our data warehouse content as a test-bed for the project to all partners. Also, to provide a description of data mining goals on these databases, contributing so to the preprocessing case-base to be developed in WP10.
Description of work
?The partners will become acquainted with the data mining goals, the nature and formal representation of the data, and the overall structure of the data warehouse at disposal,? by analyzing the available data and meta-data.
Deliverables
Two Deliverables are envisaged:
D6.1:A confidential excerpt of the data warehouse, i.e., data and meta-data (e.g., the schema description).
D6.2:A public report of the data mining goals and how to map them on the data. These "initial" preprocessing case descriptions will be implemented in WP10 and optimized by the automatic preprocessing operator in in WP3, WP4 and WP14.
Milestones and expected result
At Milestone 1 the data warehouse is available to the project partners. The analysis of the available data warehouse is clearly essential to the whole project. However, an added value shall come from a comparison of this data warehouse with other ones that some of the partners may have in house. This comparison, even though not explicitly reported upon, will help transferring the experience gained inside the project to other applications outside it.
Workpackage number :
WP7: Environment for Preprocessing
Start date or starting event:
Start +? 6
Participant number:
Dialogis
SwissLife
Person-months per participant:
12
6
???????????
Objectives
to enable an experienced user to specify an entire knowledge discovery task (data selection, pre-processing, data mining, visualization of results) as a specific sequence of sub-tasks,
to implement operators specified in workpackage 1 that were not already implemented in WP2.
Description of work
The current KDDSE is object-oriented and does not allow the specification of a sequence of actions such as random selection followed by discretization followed by some data mining analysis run. Hence, the user interface and some of the data structures as well as the control flow within it must be enhanced to achieve the above mentioned objectives. These data structures must also allow the consideration of constraints as they are implied by the meta data specified in WP8.
Deliverables
Deliverable D7 contains:
- software libraries for the enhanced graphical user interface
Milestones? and expected result
At Milestone 2, it is expected that an experienced user will be able to define an entire knowledge discovery task in one sequence, i.e. without having to construct intermediate data tables and/or execute separate preprocessing operations.
Workpackage number :
WP8: Meta-data for Preprocessing
Start date or starting event:
Start +? 6
Participant number:
SwissLife
DISTA
TILab
UniDo
Person-months per participant:
5
9
3
7.5
Objectives
To specify the meta-data needed to apply and combine the preprocessing-operations in a? syntactically correct manner. To specify, as precisely as possible, a model of the meta-data, i.e., a model of the structure, content and representation of the information the meta-data shall supply.
Description of work
For each type of pre-processing operators which, according to the outcome of WP1, has to be performed, specification of the necessary meta-data are identified and provided in a model usable in WP12. The meta model allows to characterize operators together with the input and output. The preprocessing operators cover both learning and manual operators. The operators are intended to access the database directly, hence the meta data are oriented towards database technology.
Deliverables
Deliverable D8 provides the meta-data in a formal representation, directly usable by the other workpackages.
Milestones and expected result
At Milestone2 the meta model as a basis of all further work should be established.
Workpackage number :
WP9: Internet-Based Interface to the Case-Base
Start date or starting event:
Start +? 22
Participant number:
UniDo
SwissLife
Person-months per participant:
8
1.5
Objectives
Meta-data of cases of data mining are presented in the Internet. The case base is structured according to several criteria and an ontology for the tasks of data mining is used for navigation and search in the case base.
Interested potential end-users can down load the cases and try them on their own data.
Description of work
The case base as developed in WP10 will be presented in the Internet. An ontology has to be developed which gives the upper layer of search for non-expert users. The ontology has to be made effective for the presentation and navigation in the WWW site.
The cases will then be indexed by the ontology.
Finally, we install and maintain a server which publishes knowledge discovery cases in the Internet.
Deliverables
D9: Installed server publishing cases of preprocessing using an ontology for navigation and search.
Workpackage number :
WP10: Case Base of Pre-processing
Start date or starting event:
Start +? 18
Participant number:
PSN
Person-months per participant:
9.5
Objectives
The objective of this workpackage is to produce a case base of prior data mining projects.? The purpose of this case base is to store experience from a large range of projects which may be used in a number of ways in future projects.? Previous cases should be stored as descriptions resulting from the environment for pre-processing of WP7 and WP12.? These detailed descriptions will be enhanced by a set of high level features, describing the project in broad terms, which may subsequently be used to retrieve and reuse previous cases in WP16.
Description of work
A database environment will be created for storing the case base.
A database model will be produced which allows the storage of descriptions resulting from WP7 and WP8.
A set of useful features will be added to the data model which enables the effective retrieval of cases.? This set of features will be supported by a similarity measure which allows the selection of similar cases.
The database will be filled with descriptions of previous projects at commercial partners? sites.
Deliverables
D10 includes a database containing a case base of preprocessing, and a report describing the structure of the database and its use.
Milestones and expected result
At milestone 3 a case-base containing best practice data-mining cases is usable.
Workpackage number :
WP11: Exploitation and Transfer of Results
Start date or starting event:
Start +? 6
Participant number:
PSN
UniDo
Dialogis
Person-months per participant:
3.5
5
1
Objectives
The objective of this workpackage is to market the results of the project, especially to gain broad attention for the Mining Mart and? its? "Case Base of Pre-processing" (WP10) on the Internet (WP9). The goal of this increased intention is additional input to the case base from experts from outside of the project.
Description of work
The pre-processing case base will be designed and implemented primarily for usage by data mining consultants who will be the case base's most important user group. These consultants could use the case base to improve their consultancy by relying on our initial work. Part of the exploitation plan is, therefore, to convince a number of high-profile data mining consultants that they will profit significantly from extracting solutions produced by other experts from the case-base in exchange for? inputing their experiences into the Mining Mart in a directly usable way for other users. Another important target group is the KDD-research community (e.g. projects like the ESPRIT-Project MetaL or Critikal), who could contribute their advanced research results to this library and use its best-practice real-world KDD-applications. To achieve these goals, the Mining Mart must be installed on the Internet (WP9), and a user-group established. This will be organized in conjunction with KDnet.
A workshop (possibly in conjunction with a major European KDD conference) to present the results and to attract contributions to the case base will be organized.
Deliverables
D11.0 Dissemination and Use Plan, month 6
D11.1 Workshop in year 3 (or at major KDD conference around that time)
D11.2 Best Practice Report after month 36
Milestones and expected results
At milestone 3 the Mining Mart should be operational on the Internet (WP9), and a first group of users which includes users from outside of the project will be established.
Increased public awareness of the project results through published material.
Workpackage number :
WP12: HCI to meta-data driven pre-processing
Start date or starting event:
Start +? 18
Participant number:
AiS
PSN
SwissLife
Person-months per participant:
17
12
4
Objectives
The goal of this workpackage is to provide users with a semi-automatic (graphical) interface for the specification of an entire knowledge discovery task. The case designer and the database administrator are to be supported at different levels of abstraction. The basis is the MiningMart meta model (M4) as developed by WP8.
The objective of this workpackage is to provide the case designer and the data warehouse administrator with a graphical user interface for specifying a conceptual data model (case designer creates concepts, relationships, feature attributes) and for mapping the conceptual data model to the relational data model (task of the data warehouse administrator). The human-computer interfaces need not access the M4 directly. This will increase the usability of the M4, the stability of programs using the M4 and the maintainability of code used for communication with the M4. The operationalization of M4 on the database is achieved by a compiler which generates SQL expressions or calls to external tools.
Description of work
M4 is stored in a database. To each operator, the corresponding SQL statements or call has to be prepared by integrating the operator into the compiler from M4 to database routines.
The M4 interface must provide methods for creating, reading, deleting and updating elements from the M4. It should also focus on user friendliness by providing methods for commonly executed tasks that may consist of a combination of the previously mentioned primitive methods.
Preprocessing chains have to be presented and edited.
The HCI must provide displays for viewing all concepts and relationships, the concept and relationship hierarchies and concept and relationship properties. It should also have a ?master-detail-view? showing a concept, its feature attributes and its relationships to other concepts.
Work includes the development of software, user tests, integration tests and documentation
Deliverables
D12.1 Compiler for M4 (SwissLife)
D12.2 M4 user interface ? software and documentation (PSN)
D12.3 HCI for pre-processing chains ? software and user guide (AiS)
D12.4 HCI for concepts and relationships ? software and documentation (PSN)
Milestones? and expected result
At Milestone 3 the results of this workpackage will provide a user interface that allows a user to build a conceptual data model that plays an important part in the knowledge discovery task and map this to the relational data model.
The M4 interface will provide easy to use methods for manipulating data in a M4 instance. This will increase the usability of the M4 and the stability of programs using the M4. It will form an integral part of the HCI for preprocessing chains.
Workpackage number :
WP13: Clustering and Description Logic
Start date or starting event:
Start +? 18
Participant number:
SwissLife
Person-months per participant:
3
Objectives
To develop a method to discover parts of the meta-data needed to guide multi-relational preprocessing directly from the data set to be pre-processed.?
Description of work
We use a clustering approach in Description Logic to analyze the relational structure of the database. Descriptions Logic are both: a most tractable formalism, for deduction as well as for learning, and well suited formalism for a fine grained description of the relational content of a database. In this workpackage we will scale an DL-learning approach to analyze large data sets (linear sample complexity, polynomial schema complexity) and analyze the database of WP6. This should give a much finer relational description of the data as the database schema do. We will also explore how well this description is suited to guide the automatic configuration of multi-relational pre-processing-operations (WP1 & WP15).
Deliverables
D13 provides the clustering approach able to fill a part of the meta-data model for multi-relational preprocessing as a prototype (PP) and a report (R).
Milestones and expected result
At milestone 3 it should be possible to analyze the relational structure of the datawarehouse of WP6? and show how the results can help to guide the multi-relational pre-processing operations for an application on these data.
Workpackage number :
WP14: Feature Construction and Selection
Start date or starting event:
Start +? 18
Participant number:
DISTA
UniDo
UEP
Person-months per participan1t:
16
9
7
Objectives
To provide a variety of methods and tools to perform feature selection and feature construction. Given the variety of data mining tasks, and the deeply diverse nature of the data, a data mining environment must include several alternative methods to select useful features and to possibly define new ones. Goal of this workpackage is to provide such spectrum of alternatives, ranging from Support Vector Machines to Genetic Algorithms. Also the issue of when using what will be investigated, in order to provide the user with both principled and pragmatic suggestions for his/her orientation.
Description of work
The use? of support vector machines for feature selection will be investigated. Implicitly, the support vector machine already transforms the input data into an enriched feature space via kernel functions. However, this approach can only handle the high dimensionality of the feature space, because it does not calculate on it, but uses only the inner product of the function values of the kernel functions. We shall investigate new ways of exploiting the internal feature construction for (external) preprocessing. In addition, the support vector machine weights the features according to their contribution to a classification task. We shall investigate, how this can be turned into a feature selection method.
Another approach, recently investigated in the literature exploits genetic search for feature selection [De Jong et al., ; Burns & Danyluk, 1999]. In this workpackage, we will use a previously developed multistrategy learning system to perform feature selection. The system, which works on both symbolic and? numerical data representations, follows a co-evolutive approach; it combines the exploration power of evolution coupled with a rich predicate logic-based representation language. The feature selection task will be dealt with a ?wrapper? approach [Kohavi & John 1998].
Another line of research that will be pursued is data abstraction, intended as an automated way of changing representation with respect to the level of details. Abstraction is a pervasive activity in human perception and reasoning. With few exceptions, abstraction has been investigated, up to now, in the problem solving context (Sacerdoti, 1973; Plaisted, 1981; Giunchiglia & Walsh, 1992; Ellman, 1993; Holte et al., 1996). In this workpackage we are rather interested in the role played by abstraction in data re-representation to suite a given task. It has been claimed since long that a good representation is a necessary condition for a successful problem solving [Amarel, 1986].
UEP will additionally exploit information theoretic approaches to feature selection. These methods are studied in the field of pattern recognition. The information theoretic analysis has received much attention in classical learning from examples, but has not yet been transferred to KDD tasks. UEP will do the following:
? The investigation of information measures for KDD tasks,
? their use for feature selection, and
? making them operational for KDD tasks within very large databases.
Deliverables
D14.1: A Report, describing the already existing GA-based learner, the adopted wrapper approach and the modifications necessary to specialize the learner to the task of feature selection in a very large database.
D14.2: A Prototype, a system that selects a subset of interesting features, according to a user-supplied criterion.
D14.3: A Report describing the support vector machine and the ways in which it can be used in order to construct and select the most important features.
D14.4: A report describing the use of information theoretic measures for feature selection.
D14.5: A prototype of feature selection system based on information theoretic measures.
Milestones and expected result
New methods for feature construction and selection will enhance the state of the art in machine learning.
Workpackage number :
WP15: Multi-Relational Data
Start date or starting event:
Start +? 6
Participant number:
PSN
SwissLife
UniDo
Person-months per participant:
6
5
6.5
Objectives
The objective of this work package is to examine the specific operations necessary for dealing with multi-relational data.? It builds on the work of WP1 and WP8.? Pre and post conditions for the different multi-relational pre-processing operations will be established which can subsequently be used in WP12.
Description of work
The following types of pre-processing operations for multi-relational data will be examined:
? Operations that change the data model, but do not have any real effect on the underlying structure (partial de-normalisation).? These operations are useful when working with attribute-value algorithms, or for reducing the complexity of multi-relational algorithms.
? Operations that change the data model in such a way that the underlying structure is affected.? The result of this is that new patterns may be discovered that can improve the overall performance.
The following sources of information about the usefulness of preprocessing operations will be examined:
? The relational data model, and specifically the relations and their multiplicities (1:N, N:1, N:M).
? Domain knowledge.? Results from WP5 and WP19 will be used.
? Early statistics ' about relations and their true multiplicities.? This is related to the work done in WP13.? Work done in this work package will be used as an extra source of information.
The effectiveness of each of these types of operations will be tested on real-life cases, such as the data warehouse in WP6.
Deliverables
A report outlining the effective use of pre-processing in a multi-relational environment.? Guidelines and preconditions will be given on when to apply which type of operations.
A prototype of a software module which determines the usefulness and applicability of the available multi-relational operators.? It should be possible to incorporate this module in the KDDSE, as well as in alternative multi-relational data mining tools.
Milestones and expected result
At Milestone2 meta-knowledge guiding multi-relational pre-processing should be available.
Workpackage number :
WP16:? Discretization and grouping
Start date or starting event:
Start +? 21
Participant number:
UEP
Person-months per participant:
5
Objectives
A number of data mining algorithms can work only with categorial data with a relatively small amount of distinct values. This narrows the applicability of? popular, wide-spread algorithms within the KDDSE. The goal of this workpackage is to investigate which methods addressing discretization of numeric attributes and grouping of values of categorial attributes are useful, and to provide a variety of these methods and tools.
Description of work
We will study the possibilities of both manual and machine learning based discretization and grouping. Selected methods and algorithms will be implemented as operators within the KDDSE.
Deliverables
D16.1: A Report, describing the methods for discretization and grouping.
D16.2: A? set of operators that implement selected algorithms.
Milestones and expected result
New methods for discretization and grouping will enhance the MiningMart and make it usable for wider variety of applications.
Workpackage number :
WP17: Integration, Evaluation and Technology Implementation Plan
Start date or starting event:
Start +? 18
Participant number:
TILab
SwissLife
PSN
NIT
Person-months per participant:
6
6.5
0.5
12
Objectives
For a comparison of pre-processing and mining with and without the MiningMart, end-users apply the system to the mining tasks and data described in D6. The evaluation concerns:
? Ease of using the MiningMart as assessed by the end-users,
? Speed-up of a mining task in comparison to the first investigation without using the MiningMart,
? Speed-up of pre-processing and mining itself ? do processes run faster because of direct operations on the datawarehouse? Have additional mining tasks become possible that were impossible without the MiningMart? Did the number of tupels to be loaded into the KDDSE decrease?
? The quality of mining results with and without MiningMart is compared.
Description of work
We install and integrate the project components on a common platform. We test them on the real datawarehouse of WP6. End-users of SwissLife will test how useful the MiningMart is. They will use a case of a mining task to be adapted for their real tasks on the datawarehouse.
NIT will provide the MiningMart with a new case of KDD. This case will use the given operators and will be described in terms of the meta model. During this work, NIT will closely interact with all partners of the MiningMart project in order to give early feedback.
The reuse of cases will guide the data mining process. The evaluation of usability of the meta model, the given operators and the case-base will be reported.
Deliverables
D17.0: An evaluation report for the whole MiningMart after 30 month, describing the experiences of the end-user with the MiningMart and comparing knowledge discovery with and without the MiningMart.
D17.1: Technology Implementation Plan after 32 month, indicating all potential foreground rights and exploitation intentions, including a timetable for exploitation.
D17.2: A new case for the MiningMart case base with the corresponding meta data tables and a description of the application.
D17.3 A report will summarize the experience with the MiningMart and evaluate its usability.
Milestones and expected result
At Milestone 3, the MiningMart should be usable for a data-analysis end-user, given a case in the pre-processing case-base very similar to task to be solved by the end-user. Experience of data mining applications using MiningMart is reported, containing the utility of the overall re-using approach, which is a key issue of the project.
Workpackage number :
WP18: Applicability Constraints on Learning Operators
Start date or starting event:
Start +? 18
Participant number:
UniDo
DISTA
Person-months per participant:
4.5
3
Objectives
The applicability constraints of learning operators are described with respect to data characteristics,
to query (application task) characteristics, and to the process of discovery.
The constraints will focus on conditions which prohibit a successful application. The analysis of the learning operators will hence deliver more practical results than current theoretical analyses of computational learning theory.
Description of work
Theory of machine learning will be searched for those situations which are used in proving that a particular learning task is hard. Very often, a task is only NP-complete or even PSPACE-hard in a particular situation, which is carefully designed for the (negative) proof. It is tried to find operational criteria for detecting these situations in order to give ?warning? to users.
Analysing the learning method used within the toolbox with respect to their applicability conditions in the average case is the more experimental part of this workpackage.
Both parts are combined into a well-based practical guide.
Deliverables
D18
Report on difficult situations for particular learning algorithms, both, from a theoretical and a practical point of view.
Milestones and expected result
The basis for a ?warning? functionality (?keep your fingers crossed?) of the system will be the main result of this workpackage. Users are warned whenever starting to apply a learning operator that is known to be unreliable or very slow under the conditions at hand.
Workpackage number :
WP19: Problem Modeling
Start date or starting event:
Start +? 6
Participant number:
PSN
Person-months per participant:
6
Objectives
The objective of this work package is to extend the work on domain knowledge in WP5.? Workpackage 5 aimed at examining the effects of business logic on preprocessing operations.? In WP19 we aime to better formalise such business rules by means of a range of diagrams.? These diagrams try to capturing the high level structure of the domain.? Given proper diagrams about the domain, suggestions for preprocessing operations can be generated automatically.
Description of work
Possible classes of domain knowledge will be taken from WP5 and these will be turned into one or more visual languages.
The effectiveness of diagrams as a means of communicating between domain expert and data mining expert will be examined.
Automatic ways of deriving suggestions from diagrams will be designed.
A small collection of data mining design patterns will be defined to aid the domain expert in describing the problem.
Deliverables
A report describing the methodology for formalising domain knowledge for data mining.? The report will describe the visual languages that can be used to define domain knowledge and will list a set of data mining design patterns.?
Milestones and expected result
At Milestone 2 a methodology for describing data mining problems is available to build up an retrieval method for the case to be build in WP10.
Workpackage number :
WP20: Project Management
Start date or starting event:
Start + 0
Participant number:
UniDo
Person-months per participant:
29.5
Objectives
Ensure that the 3 phases are properly coordinated and workpackages delivered in time in order to maximize the project success;
manage all the administrative procedures between the consortium and the commission including reporting to the European commission;
coordinate the NAS partners with the other MiningMart partners;
ensure information dissemination (monitor decision who participates in which event).
Description of work
Project management is organized into five tasks:
? work organization: workpackage oriented monitoring and reporting;
? quality assurance by internal workshops at the milestones;
? overall management: administrative procedures and communication with the European commission;
? project presentation via WWW;
? service to the international ?representation race?: building up and maintaining the server of pre-processing cases.
Deliverables
D20.0: Project presentation in the internet
D20.1: Report on Milestone 1
D20.2: Report on Milestone 2
D20.3: Report on Milestone 3
D20.4: Final Report
D20.5: Final Report (EXT MM)
Milestones and expected result
At milestone 3 the MiningMart should be operational on the Internet, and a first group of project external users will be established (together with WP11).
Deliverables list
Del. no.
Del. name
WP no.
Lead participant
Estimate person-months
Del. type
Security*
Delivery
(proj.
month)
D1
Pre-processing Operators Requirement Specification
1
DISTA
12
R
IST
6
D2
KDDSE
2
Dialogis
10
P
IST
6
D3
Learning about Time
3
UniDo
6
R
Pub
6
D4.1
Informed Parameter Setting
4
DISTA
4.6
R
Pub
12
D4.2
Informed Parameter Setting for Operators
4
DISTA
5
R
Pub
18
D4.3
Automatic Parameter Setting
4
DISTA
6
P
IST
18
D5
Domain Knowledge
5
PSN
3
R
IST
6
D6.1
Data warehouse confidential data
6
Swiss Life
4
P
Co
6
D6.2
Data warehouse
6
Swiss Life
4
P
Pub
6
D7
Libraries for KDDSE Environment for Pre-processing
7
Dialogis
18
P
IST
18
D8
Meta-data for Pre-processing
8
UniDo
24.5
P
IST
18
D9
Internet server for case base
9
UniDo
9.5
P
Pub
36
D10
Case-base of Pre-processings
10
PSN
9.5
P,R
Pub
36
D11.0
Dissemination and Use Plan
11
Dialogis
1
R
IST
6
D11.1
Workshop
11
UniDo
5
O
Pub
?
D11.2
Best Practice Report
11
PSN
3.5
P
Pub
36
D12.1
Compiler for M4
12
SwissLife
4
P
IST
36
D12.2
M4 Interface
12
PSN
5
P,R
Pub
30
D12.3
HCI for pre- processing
12
AiS
17
P,R
Pub
36
D12.4
Concept Editor
12
PSN
7
P,R
Pub
36
D13
Clustering and Description Logics
13
Swiss Life
3
R
Pub
30
D14.1
Feature Selection
14
DISTA
4
R
Pub
24
D14.2
Feature Construction and Selection
14
DISTA
12
P
Pub
36
D14.3
Feature Construction and Selection Algorithm
14
DISTA
9
R
Pub
36
D14.4
Feature Selection based on Information Theoretical measures
14
DISTA
3
P
IST
38
D14.5
Feature Selection Algorithm
14
DISTA
4
R
IST
38
D15.1
Multi-relational Data
15
PSN
6
R
IST
18
D15.2
Pre-processing Multi-relational Data
15
PSN
11.5
P
IST
18
D16.1
Report on discretization and grouping
16
UEP
2
R
IST
38
D16.2
Operator implementation for discretization and grouping
16
UEP
3
P,R
IST
38
D17.1
Technology Implementation Plan
17
TILab
2
R
Pub/Int.
38
D17.2
Discovery case modelled
17
TILab
8
P
IST
38
D17.3
Evaluation report
17
TILab
4
R
Pub
38
D18
Applicability Constraints on Learning Operators
18
UniDo
7.5
R
Pub
36
D19
Problem Modelling
19
PSN
6
R
IST
18
D20.0
Project presentation
20
UniDo
0.5
O
Pub
3
D20.1
Milestone report
20
UniDo
0.5
R
IST
8
D20.2
Milestone report
20
UniDo
0.5
R
IST
20
D20.3
Milestone report
20
UniDo
0.5
R
IST
37
D20.4
Final Report
20
UniDo
1.0
R
Pub
38
D20.5
Final Report (EXT)
20
UniDo
1.0
R
Pub
39
*Int.??????? Internal circulation within project (and Commission Project Officer if requested)
? Rest.???? Restricted circulation list (specify in footnote) and Commission PO only
? IST??????? Circulation within IST Programme participants
? FP5????? Circulation within Framework Programme participants
? Pub.????? Public document
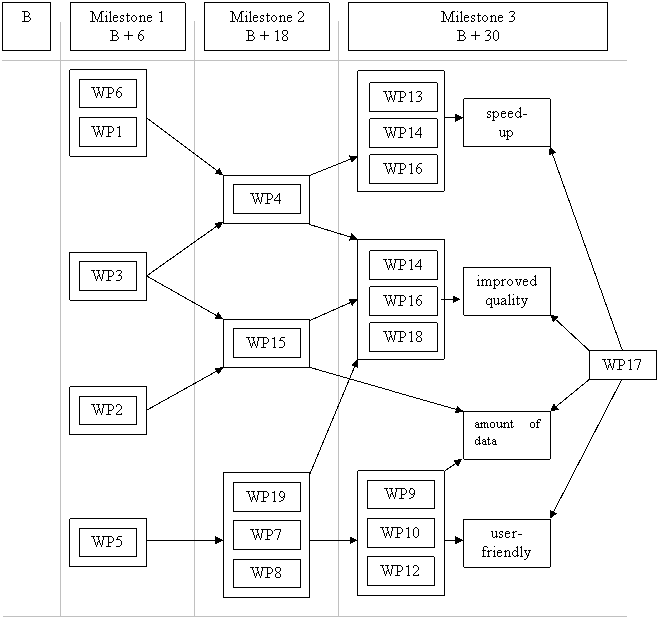 |
The following figure shows the system that will be developed as it will look at the third milestone. The workpackages are indicated.
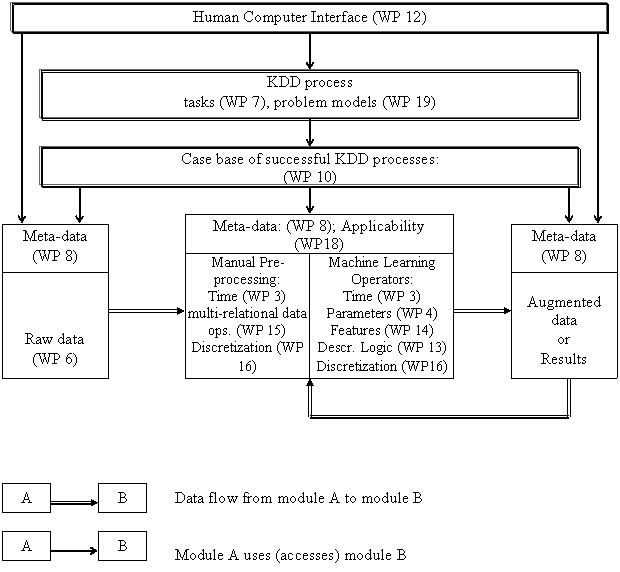
![]()
Project management is oriented towards the European Commission, the project partners, and the international scientific community.
Of course, project results and activities will be reported to the European commission. The co-ordinator sends a progress report every 3 months to the European Commission. Cost statements are sent every 6 months to the European Commission.
In order to manage the work of the project effectively, the project is structured into phases with milestones at the end. Along with each milestone, an internal workshop of the project will be held (B+7, B+19, B+36).? The workshops serve the following purposes:
? integration of software
? providing all partners with the current version of the MiningMart system,
? assess the quality of the project according to the success criteria written in section 2.5,
? decide on actions to be taken in order to maintain or enhance the quality,
? decide on actions for information dissemination (who participates in which conference, fare,...).
The coordinator invites the partners at least 6 weeks before the workshop. Deliverables including software need to be 1 month before the workshop at the coordinator. Minutes of the workshop are sent to the Commission and the partners immediately after the workshop. In the following, the decisions of the workshop will be monitored by the coordinator who also makes sure that decided actions are in fact taken.
Workpackages are clearly mapped onto the corresponding phases. Regarding this flow of work, project management has to monitor the progress of work, make sure that deadlines are met, and the basis for the following phase is available for all partners, in time. Progress of the project will be monitored according to the checklist given in section 2.5 Success Criteria.
The partners of one workpackage report to its leading contractor, who reports to the coordinator. Should it happen that a deliverable or cost statement of a partner is not sent in time, the coordinator may decide to not include the corresponding costs of this partner in the cost statement sent to the commission, this having the effect that the partner is (partially) not refunded. In order to not let this situation happen, in case of problems and necessary changes of the workplan, the partners of a workpackage first aim at solving the problem among themselves, in time. Only if this should fail, the coordinator plays an active role in finding a solution.