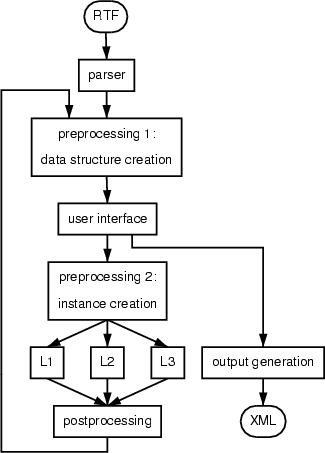
Um aus RTF-Dokumenten strukturierte XML-Dokumente zu generieren m?ssen die Daten, die sich durch die RTF-Texte ergeben, mehrfach aufgearbeitet werden, bevor die durch Anwender gegebenen Beispielklassifikationen von einem Lernalgorithmus genutzt werden k?nnen. Die Aufbereitung der Daten erfolgt dabei in den beiden »Preprocessing«-Schritten data structure creation und instance creation.
Im Diagramm ist zu erkennen, dass im System eine Schleife realisiert wurde, durch die alle Phasen vom »Preprocessing 1« bis zum »Postprocessing« beliebig wiederholt werden k?nnen. Den sich hierdurch ergebenden Vorteil und weitere Details beschreiben die folgenden Abschnitte.