Ein Entscheidungsbaum hat Kanten, an denen Attributwerte stehen, Konten sind Verzweigungspunkte und Bl?tter stellen Klassifikationen dar. Um zu entscheiden, ob ein neues Beispiel zu einer Klasse geh?rt, wird den Kanten gefolgt, deren Beschriftung einem Attributwert des Beispiels entspricht, bis ein Blatt erreicht ist [MORIK 1995]. Eine der wesentlichen Eigenschaften der Klassifikation ist dabei die Diskretisierung. D.h. die einzelnen Klassen sind scharf von einander getrennt, so dass ein Fall, bestehend aus einzelnen Werten, entweder zu einer Klasse geh?rt oder nicht.
Um einen Entscheidungsbaum aufzubauen, muss der Algorithmus f?r jeden Konten berechnen, welches Attribut ihm zugewiesen wird. Dies ist das zentrale Auswahlproblem von ID3. Es muss entschieden werden, welches Attribut den gr??ten Informationsgewinn bringt, um die Trainingsdaten bestm?glich zu klassifizieren. Ist das Problem gel?st, wird das Attribut ausgew?hlt und f?r jeden m?glichen Wert des Attributs wird eine Kante mit Kindknoten erzeugt. Das ausgew?hlte Attribut kann nun aus der Liste aller Attribute entfernt werden. Die Kindknoten werden weiter nach dem gleichen Schema rekursiv unterteilt, bis in den Knoten nur noch Objekte einer Klasse stehen. Diese Knoten bilden die Bl?tter des Baumes, welche die Klassenkennzeichnung des entsprechenden Objektes enthalten.
Der Informationsgehalt eines Attributs st?tzt sich auf die, aus der Informationstheorie stammenden Gr??e, Entropie. Sie berechnet sich nach [MORIK 1995] mit der Formel:
Der Informationsgewinn eines Attributs ergibt sich durch den Vergleich24 der Entropie des Attributs mit der Entropie der Trainingsmenge. So ist es m?glich das Attribut mit dem gr??ten Informationsgehalt zu bestimmen und auszuw?hlen.
Der Aufbau eines optimalen Entscheidungsbaumes ist nach [HYAFIL . RIVEST 1976] NP-vollst?ndig, d.h. das Problem kann nicht mit Hilfe eines deterministischen Algorithmuses in polynomineller Laufzeit berechnet werden. Der ID3 Algorithmus benutzt einen nonbacktracking greedy Algorithmus, was bedeutet, dass das zu w?hlende Attribut immer auf der Basis des momentanen Wissenstands bestimmt wird. Auch wenn sich sp?ter vielleicht herausstellen w?rde, dass die Wahl eines anderen Attributes g?nstiger gewesen w?re.
Zur Illustration des Algorithmuses wird als n?chstes, an einem kleinen Beispiel, ein Entscheidungsbaum hergeleitet [MITCHELL 1997]. Die Tabelle 6.1 beschreibt, ob es an bestimmten Samstagmorgenden m?glich war, Tennis zu spielen oder nicht.
Um die Entropie der Beispielmenge zu berechnen, betrachtet man die Spalte »Tennis spielen?« (Zielattribut).
Berechnung der Entropie f?r Aussicht:log2
log2
Entropie der Beispielmenge = - (- 0, 4098 - 0, 5305) =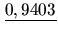
sonnig:
log2
log2
Summe mit umgekehrtem Vorzeichen: 0, 971
bew?lkt:
log2
Regen:Entropie f?r Aussicht:
Summe mit umgekehrtem Vorzeichen: 0, 971
Die Informationsgewinne der anderen drei Attribute berechnen sich analog:
Informationsgewinn (Temperatur) = 0,029 Informationsgewinn (Luftfeuchtigkeit) = 0,151 Informationsgewinn (Wind) = 0,048
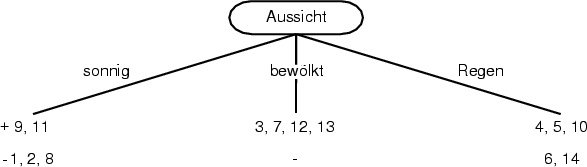
Die Berechnungen des Informationsgewinns der einzelnen Attribute zeigen, dass das Attribut Aussicht am Besten geeignet ist um die Daten zu ordnen. Wenn Aussicht ausgew?hlt wurde, werden drei Kanten angelegt und mit sonnig, bew?lkt und Regen beschriftet. Der unter bew?lkt gebildete Knoten enth?lt nur positiv klassifizierte Beispiele und wird damit zum Blatt (siehe Abbildung 6.1).
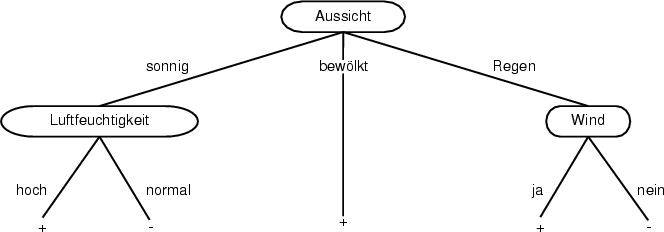
Der unter sonnig und Regen gebildete Knoten muss genau wie der oberste behandelt werden. Am Ende ergibt sich der in Abbildung 6.2 abgebildete Entscheidungsbaum.