Die Klasse Tokenizer.java ?bernimmt die Aufgabe eines Scanners. Die
einzelnen Zeichen des Eingabedokuments werden von ihm gelesen. Abh?ngig von
der Art des Zeichens werden daraufhin Teilzeichenketten, so genannte Tokens,
zusammengesetzt.
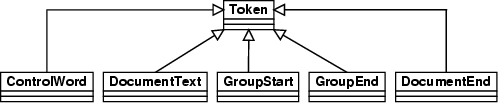
Der Tokenizer unterscheidet die folgenden f?nf Klassen von Tokens:
ControlWord
Ergeben die gelesen Zeichen ein Kontrollwort
der RTF-Syntax, bilden sie ein Token das durch die Klasse ConrolWord.java repr?sentiert wird.
DocumentText
Der eigentliche Text des Dokumentes wird durch
Tokens der Klasse
DocumentText.java dargestellt.
GroupStart
Findet der Tokenizer bei der Analyse des Textes eine
?ffnende Geschweifteklammer, so handelt es sich um den Beginn einer
Gruppe. Der Gruppenstart wird durch ein Token der Klasse GroupStart.java repr?sentiert.
GroupEnd
Findet der Tokenizer bei der Analyse des Textes eine
schlie?ende Geschweifteklammer, so handelt es sich um das Ende einer
Gruppe. Das Gruppenende wird durch ein Token der Klasse GroupEnd.java repr?sentiert.
DocumentEnd
Liefert die Klasse FileHandler.java keine
Zeichen mehr, sondern gibt das Ende der Datei bekannt, wird das Token DocumentEnd erzeugt.
Abbildung 8.2:
UML Diagramm der Klassen die die einzelnen
Tokens realisieren. Die Methoden und Attribute sind hier aus Gr?nden der
?bersicht nicht dargestellt.
Die zuvor genannten Klassen sind in Abbildung 8.2
dargestellt. Da die Klassen einige Eigenschaften gemeinsam aufweisen, erben
sie diese von der Klasse Token.java. Spezialisierungen sind in den
einzelnen Unterklassen implementiert.
Damit die genannten Tokens aber erst einmal erkannt werden, liest der
Tokenizer jedes einzelne Zeichen. F?r diesen Vorgang wurden zwei wichtige
Methoden implementiert:
readChar():int
peekChar(int i):int
Die Methode readChar():int liest das n?chste Zeichen ein. Mit der
Methode
peekChar(int i) ist es wiederum m?glich nachzuschauen, welches
Zeichen als n?chstes gelesen wird, ohne es zu lesen29. Der
Parameter i gibt dabei an, wie viele Zeichen »vorhergesagt« werden
sollen. Der Tokenizer wurde mit einem Lookahead von zwei Zeichen
implementiert, so dass i die Werte 0 und 1 annehmen kann. Zu wissen, welche
Zeichen als n?chstes gelesen werden, ist beispielsweise bei der Behandlung von
Sonderzeichen oder Umlauten in Dokumenten wichtig:
Die privaten Methoden readChar() und peekChar(int i) werden also
f?r die Erzeugung der verschiedenen Tokens und zur Behandlung von
Sonderzeichen genutzt. Der Parser selbst kann nun die erstellten Tokens verarbeiten
und braucht sich nicht mehr um einzelne Zeichen zu k?mmern.
Analog zu den oben genannten Methoden f?r einzelne Zeichen stehen hierf?r
folgende Methoden zur Verf?gung:
peekType(int i):int
liefert den Typ des n?chsten bzw. des
?bern?chsten Tokens, ohne das weitere Zeichen aus dem Datenstrom gelesen
werden m?ssen.
peekToken(int i):Token
liefert das n?chste bzw. das
?bern?chste Token, ohne das weitere Zeichen aus dem Datenstrom gelesen
werden m?ssen.
readToken():Token
liefert das n?chste Token und veranlasst die
Erzeugung eines neuen Tokens wof?r weiter Zeichen aus dem Datenstrom
gelesen werden.
Die Hauptaufgabe des Tokenizers, aus dem einzulesenden Text Teilstrings zu
bilden, kann mit den vorgestellten Methoden erledigt werden.