| Description: |
One approach to inductive inference of clauses is inverting resolution
steps. In this scenario, for each given (positive) example, not explained by
background knowledge LB, yet, another clause is added to
LB. The basic step for this procedure is illustrated by
figure 1.
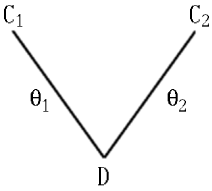
Figure 1: The Resolution-"V".
The "V" shows a single resolution step. The two arms represent
the clauses C1 and C2, the derived
clause, named D, stands at the bottom.
Additionally, the substitutions θ1 and θ2,
needed to perform the resolution step, are attached to the arms of the
"V".
To be able to perform a resolution step, a literal L has to exist,
such that
Then we can derive
D := ( C1θ1 \ L ) ∪
( C2θ2 \ ¬L )
from C1 and C2.
Now we are interested in inverting such a resolution step.
Let's assume C1 and D are given, and we
are looking for a clause C2, to add it to the
background knowledge LB, such, that the clause
D can be derived from LB.
Let's have a look at what we can say about C2, in
this setting:
- For each literal L' ∈ D \ ( C1θ1
) we know L' ∈ C2θ2,
because of the upper equation, defining D.
- A literal Lθ1, with L ∈
C1θ1 and
¬L ∈ C2θ2,
can be found by
- comparing D to C1 and
- choosing a literal from D that is "missing"
in C1.
- Obviously we do not know anything about θ2.
The easiest choice is θ2 = ∅.
- For each literal
L'' ∈ ( C1θ1 \ L )
we cannot determine whether
L'' ∈ ( C2θ2 \ ¬L ).
These points show, on the one hand, that candidates for
C2 are easily constructed, e.g.:
C2 := D \ ( C1θ1 )
∪ ¬L, with
θ2 := ∅.
On the other hand they show, that in general,
- the number of possible choices (except renamings) for
C2 might be exponential in the length of clauses,
and
- that the invertion of the substitution θ2
requires even more choices,
which is bad in this setting, because it leads to a larger set of
hypotheses.
For practical use, this drawbacks demand incorporation of preference
criterions or further assumptions.
|